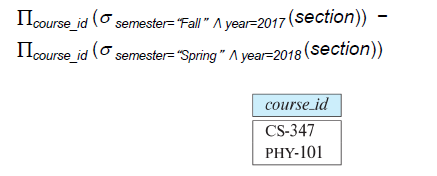Outline 1. Accessing SQL From a Programming Language 2. Functions and Procedures 3. Triggers 4. Recursive Queries 5. Advanced Aggregation Features
Accessing SQL from a Programming Language
A general purpose program은 함수( Java의 메서드) 등을 사용하여 database server와 연결합니다.
Embedded SQL은 프로그램이 database server와 상호 작용할 수 있는 수단을 제공합니다.
JDBC
SQL을 지원하는 Database Systems와 연동할 수 있는 JAVA API 입니다.
쿼리 날리기, 업데이트 등의 기능을 지원합니다.
데이터베이스에 존재하는 릴레이션 이름과 유형 등 메타데이터 검색 기능도 제공합니다.
SQL Injection
SQL 인젝션(SQL 삽입, SQL 주입)은 코드 인젝션의 한 기법으로클라이언트의 입력값을 조작하여 서버의 데이터베이스를 공격할 수 있는 공격방식을 말합니다.
사용자가 입력한 데이터를 제대로 필터링, 이스케이핑하지 못했을 때 발생합니다.
Prepared statement 객체를 사용하여 사용자의 입력값을 파라미터로 넘겨주는 방식을 사용하는 것이 좋습니다.
PreparedStatement pStmt = conn.prepareStatement ( "insert into instructor(?,?,?,?)");
// 사용자가 입력한 값을 파라미터로 전달합니다
pStmt.setString (1, "88877");
pStmt.setString (2, "Perry");
pStmt.setString (3, "Finance");
pStmt.setInt (4, 125000);
Declaring SQL Functions
함수와 프로시저를 통해 "비즈니스 로직"을 데이터베이스에 저장하고 SQL 문에서 실행할 수 있습니다.
# FUNTION 정의 - input : 부서명 output : 해당 부서에 속한 instructor의 수
CREATE FUNCTION dept_count(dept_name VARCHAR(20))
RETURNS INTEGER
BEGIN # BEGIN은 '{'라고 생각하면 편합니다.
DECLARE d_count INTEGER;
SELECT COUNT(*) INTO d_count
FROM instructor
WHERE instructor.dept_name = dept_name
RETURN d_count;
END # '}'
# FUNCTION 사용
# instructor > 12인 모든 department의 name, budget을 찾는 쿼리
select dept_name , budget
from department
where dept_ count (dept_name ) > 12;
Table Functions
TABLE을 반환하는 Function을 table functions라고 합니다. ( SQL 표준 )
# Input : dept_name , output : instructor 테이블
create function instructor_of (dept_name char (20))
returns table ( # 반환할 테이블의 속성 정의
ID varchar (5),
name varchar (20),
dept_name varchar (20),
salary numeric (8,2))
return table # 아래 쿼리 결과를 반환합니다.
(select ID, name, dept_name, salary
from instructor
where instructor.dept_name = instructor_of.dept_name);
# Usage
SELECT *
FROM TABLE (instructor_of('Music'));
Language Constructs
# LOOP 문
LOOP
처리문;
EXIT 탈출 조건;
END LOOP;
# WHILE 문
WHILE 조건
LOOP
처리문;
END LOOP;
# FOR 문
FOR 증감변수 IN 초깃값..최종값
LOOP
처리문;
END LOOP;
External Language Routines
SQL에서는 JAVA, C#, C, C++ 등으로 정의된 함수를 가져와서 쓸 수 있습니다.
create procedure
dept_count_proc (in dept_name varchar (20),
out count integer)
language C
external name '/usr/avi/bin/dept_count_proc'
create function dept_count(dept_name varchar (20))
returns integer
language C
external name '/usr/avi/bin/dept_count'
Security with External Language Routines
Use SandBox techniques : 데이터베이스 코드의 다른 부분에 액세스하거나 손상시키는 데 사용할 수 없는 Java와 같은 안전한 언어를 사용합니다.
데이터베이스 프로세스 메모리에 액세스하지 않고 별도의 프로세스에서 외부 함수/프로시저를 실행합니다.
Triggers
트리거(Trigger)는 데이터베이스 테이블에 발생하는 데이터 변경 이벤트에 대해 자동으로 반응하여, 특정 작업을 수행하는 데이터베이스 객체입니다.
트리거 메커니즘을 설계하기 위해 다음을 수행해야 합니다. 1. 트리거를 수행할 조건을 지정합니다. 2. 트리거가 실행될 때 수행할 작업을 지정합니다.
Trigger to Maintain credits_earned value
# Trigger example
CREATE TRIGGER credits_earned # credits_earned라는 트리거를 생성
AFTER UPDATE OF takes ON (grade) # takes 테이블의 grade 열이 업데이트될 때마다 실행됩니다.
REFERENCING NEW ROW AS nrow # 새로운 행(nrow)과 이전 행(orow)을 참조
REFERENCING OLD ROW AS orow
FOR EACH ROW
WHEN nrow.grade <> 'F' AND nrow.grade IS NOT NULL # 새로운 값이 F나 NULL이 아니면서
AND (orow.grade = 'F' OR orow.grade IS NULL) # 예전 값이 F나 NULL인 경우
BEGIN ATOMIC # 트리거의 본문 시작, 트렌젝션을 정의합니다.
UPDATE student # 총 이수 학점을 업데이트 합니다.
SET tot_cred = tot_cred +
(SELECT credits
FROM course
WHERE course course_id = nrow.course_id)
WHERE student.id = nrow.id
END; # 트리거 본문이 끝나는 지점
Statement Level Triggers
일반적으로, 트리거는 각 행이 수정될 때마다 작동합니다. 따라서 대량의 행이 업데이트될 때는 성능 저하가 발생할 수 있습니다. 하지만, for each statement 구문을 사용하면 한 번에 여러 행을 처리할 수 있으므로, 대량의 행이 업데이트될 때 더 효율적인 처리가 가능합니다.
referencing old table 또는 referencing new table 구문을 사용하여, 이전 및 새로운 버전의 테이블을 참조할 수 있습니다.
이전 및 새로운 테이블은 트랜잭션 내에서 변경된 행의 모든 버전을 포함하는 일시적인 테이블입니다. 이러한 일시적인 테이블을 전이 테이블(transition table)이라고 합니다.
When Not To Use Triggers
데이터베이스에서 요약 데이터를 유지 관리하는 materialized view 기능을 제공합니다.
데이터베이스에서 복제게 대한 기본 지원을 제공합니다.
Encapsulation (캡슐화)를 사용하면 트리거를 사용하지 않고도 필요한 작업을 효과적으로 수행할 수 있습니다. - 필드를 업데이트하는 메서드를 정의합니다. - 업데이트 메서드로 작업을 수행할 수 있습니다.
Cascading execution : 트리거 호출로 의도치 않은 트리거가 연쇄적으로 실행될 수 있고, 이로 인해 잘못된 데이터를 로딩하는 등의 문제가 발생할 수 있습니다.
Recursive Queries
이행폐포(transitive closure) : 이행폐포는 관계형 데이터베이스에서 두 레코드 간의 관계를 탐색하는 연산 중 하나입니다. 이를 이용하면, 한 레코드와 직접적으로 연결된 다른 레코드를 찾을 뿐만 아니라, 그들 사이의 간접적인 관계를 찾을 수 있습니다. 이헹폐포의 예시 ) 방향 그래프에서 한 노드에서 다른 노드로 이동할 수 있는 모든 경로를 찾는 것
SQL에서는 다음과 같이 재귀를 통하여 이행폐포를 구할 수 있습니다.
# 특정 과목의 모든 선수 과목을 직접적으로 또는 간접적으로 찾는 방법, 특정 과목의 이행폐포 찾기
# 생성되는 rec_prereq가 prereq 테이블의 이행 폐포입니다.
with recursive rec_prereq (course_id , prereq_id) as # 쿼리에서 임시로 사용가능한 재귀적 테이블 생성 req_prereq 속성은 (course_id , prereq_id)입니다.
select course_id , prereq_id # Non-Recursive 이 코드로 course_id와 prereq_id를 선택하여 새로운 rec_prereq 테이블을 만듭니다.
from prereq
union # Recursive
select rec_prereq course_id , prereq prereq_id ,
from rec_rereq , prereq
where rec_prereq prereq_id = prereq course_id
)
select *
from rec_prereq;
Advanced Aggregation Features
Ranking
rank()를 사용하여 투플들에게 순위를 부여할 수 있습니다. rank() = 1,1,3,4 ( 중복 값에 대해 같은 순위, 그 다음순위는 중복순위 + 중복값 개수)
dense_rank()를 사용하면 순위를 빼곡하게 채워줍니다. dense_rank() = 1,1,2,3 ( 중복 값에 대해 같은 순위, 그 다음순위에는 중복순위 + 1)
row_number()는 rank()와 달리 중복 값을 허용하지 않습니다. row_number() = 1,2,3,4 ( 중복 값에도 다른 순위)
# RANK(), GPA 내림차순으로 순위를 정합니다.
SELECT ID , RANK () OVER (ORDER BY GPA DESC ) AS s_rank
FROM student_grades;
# RANK()로 순위를 정했고, 그것을 정렬해서 보고싶으면 ORDER BY 구문을 추가합니다.
SELECT ID , RANK () OVER (ORDER BY GPA DESC ) AS s_rank
FROM student_grades
ORDER BY s_rank;
Ranking ( Cont.)
OVER()내부에 PARTITION BY를 사용하여 그룹을 짓고 그룹마다 순위를 정할 수 있습니다.
ntile() : ntile() 함수는 정렬된 행(row)을 n개의 구간(bucket)으로 분할하고, 차례대로 행 번호를 부여합니다. - 만약 전체에 12개의 투플이 존재하고, ntile(5)를 하는 경우에 5개의 그룹이 생성됩니다. 그리고 나머지가 0이 될 때까지 첫번째 그룹부터 한개씩 행을 추가합니다. 이 경우에는 1, 2번 그룹에서 각각 행을 1개씩 더 가지게 됩니다.
select ID , dept_name,
rank () over ( partition by dept_name order by GPA desc )
as dept_rank
from dept_grades
order by dept_name , dept_rank;
# ntile()
select ID , ntile (4) over ( order by GPA desc ) as quartile
from student_grades
Windowing
# date 오름차순 순서로 해당일, 전날, 다음날의 value의 합을 계산합니다.
SELECT (date, sum value ) OVER
(ORDER BY date BETWEEN ROWS 1 PRECEDING AND 1 FOLLOWING)// BETWEEN (1개 앞의 행 ~ 1개 뒤의 행)
FROM sales;
between rows unbounded preceding and current : 이전 모든 행(첫번째 행) ~ 현재 행
rows unbounded preceding : 현재 행 앞의 모든 행
range between 10 preceding and current row : 현재 행의 10번째 앞 행 ~ 현재 행
range interval 10 day preceding : 현재 행의 1일전 , 2일전 ,..., 10일 전의 행
Outline 1. Join Expressions 2. Views 3. Transactions 4. Integrity Constraints 5. SQL Data Types and Schemas 6. Index Definition in SQL 7. Authorization
Joined Relations
조인 연산은 두 개의 릴레이션을 대상으로 수행하며 결과적으로 새로운 하나의 릴레이션을 생성하는 연산입니다.
조인 연산은 일반적으로 FROM 절의 subquery 수행에 사용된다고 합니다.
조인에는 다음 3가지 종류가 존재합니다. ( Natural Join / Inner Join / Outer Join )
Natural Join in SQL
자연 조인 ( Natural Join )은 두 개 이상의 데이터베이스 테이블에서 공통적인 칼럼(열)을 기반으로 조인하는 방법 중 하나입니다. 이 때, 공통 칼럼을 자동으로 인식하여 해당 칼럼을 기반으로 두 테이블을 조인합니다.
조인할 칼럼의 이름과 데이터 형식이 일치해야 합니다.
# Natural Join Example
SELECT name, course_id
FROM studetns, takes
WHERE student.ID = takes.ID;
# 동일한 쿼리 ( Natural Join 사용 )
# 공통 속성(ID)를 자동으로 인식하여 조인을 수행합니다.
SELECT name, course_Id
FROM student NATURAL JOIN takes;
# 여러 테이블을 자연 조인하는 경우
# (r1과 r2가 자연 조인하여 생성된 테이블) NATURAL JOIN r3 ... 이런 식으로 순차적으로 조인
SELECT A1, A2, ... , An
FROM r1 NATURAL JOIN r2 NATURAL JOIN ... NATURAL JOIN Rn
WHERE P;
다음과 같이 공통 속성이2개 이상인 경우모든 공통 속성의 값이일치하는 투플들만 매칭시킵니다.
릴레이션 a ( A,B,D )
릴레이션b ( A, B, C)
a NATURAL JOIN b - 공통 속성 A, B를 기준으로 두개 모두 값이 같은 투플들만 매칭시킵니다.
Dangerous in Natural Join
Natural Join은 공통 칼럼을 자동으로 인식하여 조인하기 때문에 의도하지 않은 컬럼이 조인에 사용될 수 있습니다.
# 학생 이름과 그들이 들은 course를 나열
# Correct Version
SELECT name, title
FROM studetn NATURAL JOIN takes, course
WHERE takes.course_id = course.course_id;
# Incorrect Version
SELECT name, title
FROM student NATURAL JOIN takes NATURAL JOIN course;
Incorrect Version : course에 department 정보가 담겨있고, student에도 department정보가 담겨있다고 가정하겠습니다. 즉, 두 릴레이션에 department_id와 같은 공통 컬럼이 존재한다면 natural join에 해당 컬럼이 반영될 것입니다. 만약 어떤 student가 자신이 속한 department가 아닌 다른 department의 course를 수강하는 경우 해당 자연 조인 결과에서 department_id가 달라 탈락하게 되고, 의도한 결과를 내지 못할 수 있습니다.
# USING 절을 이용하여 조인에 참여할 속성을 지정하기
SELECT name, title
FROM student NATURAL JOIN takes JOIN course USING (course_id);
Natural Join은 모든 공통 컬럼에 대해 조인을 수행합니다. USING을 사용하면 조인에 사용할 컬럼을 지정할 수 있습니다.
Outer Join
정보의 손실을 방지하는 조인 연산의 확장판입니다.
기존에는 조인 속성의 값이 일치하지 않는 경우 결과 릴레이션에서 제외되었지만, Outer Join을 사용하면 매칭되지 않은 데이터도 결과에 반영할 수 있습니다. 이 때 null 값을 사용하여 매칭되지 않은 빈 자리를 채웁니다.
LEFT OUTER JOIN / RIGHT OUTER JOIN / FULL OUTER JOIN 이 존재합니다.
Joined Types and Conditions
Join Types : Join condition으로 Join을 했을 때 매칭되지 않은 투플들을 어떻게 처리할 것인지 정의합니다. INNER JOIN , LEFT OUTER JOIN , RIGHT OUTER JOIN , FULL OUTER JOIN
Join Conditions : 두 릴레이션의 어떤 데이터를 Match할건지 정의 Natural , ON < predicate >, Using ( A1, A2, ... , An)
Joined Relations – Examples
1. natural right outer join
2. inner join
Inner Join 과 Natural Join의 차이점
Inner Join은 On을 사용하여 조건을 지정할 수 있습니다.
Natural Join은 결과로 조인에 사용된 공통 속성( 중복되는 속성 )을 하나만 남깁니다.
Inner Join은 결과에 두 테이블의 모든 속성을 표기합니다. ( 중복되는 속성도 표기 )
Views
데이터의 일부만을 특정 사용자에게 제공하거나, 데이터의 일부를 가공한 결과를 제공하고자 할 때 사용합니다.
물리적 저장장치에는 존재하지 않으며 논리적으로 존재하는 가상의 릴레이션입니다.
View Definition
# v : view name , query expression의 결과 테이블을 v라는 이름의 가상 테이블로 사용한다는 의미
CREATE VIEW v AS < query expression >
뷰는 위와 같이 정의하여 사용할 수 있습니다.
뷰는 쿼리를 저장하는 것입니다. 즉 , 뷰를 사용할때 해당 부분이 쿼리로 대체되어지고 이로 인해 항상 최신 정보를 유지할 수 있습니다.
View Definition and Use
# salary를 제외한 instructor 릴레이션 뷰 생성
CREATE VIEW faculty AS
SELECT ID, name, dept_name
FROM instructor;
# 뷰 사용하기
SELECT name
FROM faculty
WHERE dept_name = 'Biology';
# department별 salary의 total을 가진 뷰 생성하기, 명시적으로 속성 이름을 부여할 수 있습니다.
CREATE VIEW departments_total_salary(dept_name, totla_salary) AS
SELECT dept_name, SUM(salary)
FROM instructor
GROUP BY dept_name;
View Definition and Using Other Views
view v1을 정의하는 식에 view v2가 사용되는 경우입니다. ( depend directly on)
v1이 v2에게 depend directly 하거나 depend path가 있는 경우입니다. ( depend on)
자기 자신에게 depend 하는 경우 v는 recursive하다고 합니다. (recursive)
# physics_fall_2017 뷰 생성
CREATE VIEW physics_fall_2017 AS
SELECT course.course_id, sec_id, building, room_number
FROM course, section
WHERE course.course_id = section.course_id
and course.dept_name = 'Physics'
and section.semester = 'Fall'
and section.year = '2017’;
# physics_fall_2017 뷰 생성
CREATE VIEW physics_fall_2017_watson AS
SELECT course_id, room_number
FROM physics_fall_2017
WHERE building= 'Watson';
# View는 접근시마다 쿼리로 치환되어 현재성을 유지할 수 있습니다.
create view physics_fall_2017_watson as
select course_id, room_number
from (select course.course_id, building, room_number
from course, section
where course.course_id = section.course_id
and course.dept_name = 'Physics'
and section.semester = 'Fall'
and section.year = '2017')
where building= 'Watson';
Materialized Views
뷰가 정의될 때 그것의 복사본을 물리적으로 저장한 것 : Materialized View
Materialized Views(실체화뷰)는 쿼리 연산 비용이 크고 릴레이션 자체의 계산 빈도가 적은 경우 사용합니다.
기존 릴레이션이 변경되는 경우 데이터 불일치 등이 일어날 수 있으며 Materialized Views를 최신 상태로 유지하기 위한 기법이 필요합니다. ( 수동으로 뷰를 새로고침하거나, 기반 릴레이션 수정시마다 뷰가 업데이트되도록 (즉시 수정) 트리거를 사용한 방법 )
Transactions
트랜잭션은 데이터베이스의 작업 단위입니다.
SQL 표준에서 트랜잭션은 SQL이 시작될 떄 암묵적으로 실행됩니다.
트랜잭션 종료 Commit work : 트랜잭션에 의해 수행된 updates가 영구적으로 저장됩니다. Rollback work : 트랜잭션에 의해 실행된 updates가 취소됩니다.
Atomic Transaction : 전부 실행되거나 아예 실행되지 않아야 합니다. ( All or Nothing )
Isolation : 다른 트랜잭션들에게 영향을 받지 않습니다.
Integrity Constraints
무결성 제약조건은 DB에 승인된 변경사항으로 인해 데이터의 일관성이 깨지는 것을 방지합니다.
unique : 각 투플이 고유한 값을 가지도록 합니다 ( 식별자 ) , 기본적으로 null을 허용합니다.
check ( P ) : 릴레이션의 모든 투플이 만족해야하는 Predicate를 정합니다.
# NOT NULL Constraints
name VARCHAR(20) NOT NULL
budget NUMERICA(12, 2) NOT NULL
# UNIQUE Constraints
UNIQUE (A1, A2, ... , Am)
# Check 절
CREATE TABLE section
(
sec_id VARCHAR(8),
semester VARCHAR(6),
# semester이 fall, winter, spring, summer중 하나의 값만을 가질 수 있도록 설정
CHECK(semester IN('Fall','Winter','Spring','Summer')
);
Referential Integrity
참조 무결성 제약조건 ( 외래키 제약조건 ) : 외래키의 값은 참조 가능한 값이어야 합니다. ( null 혹은 참조 되는 릴레이션의 도메인 )
# 외래키를 생성하여 다른 테이블을 참조할 수 있습니다.
FOREIGN KEY (dept_name) REFERENCES department
# 외래키의 속성 목록을 명시적으로 지정할 수 있습니다.
FOREIGN KEY (dept_name) REFERENCES department (dept_name)
Cascading Actions in Referential Integrity
어떤 작업으로 인해, 참조 무결성 제약조건을 위반하는 경우 해당 작업이 취소됩니다.
delete나 update시 cascade를 지정하여 해결할 수 있습니다.
Set null, Set default를 사용하면 null 값 또는 default 값으로 외래키가 채워집니다.
# 부모 : 참조되는 투플 , 자식 : 참조하는 투플
CREATE TABLE course(
...
dept_name VARCHAR(20),
FOREIGN KEY(dept_name) REFERENCES department
ON DELETE CASCADE # 부모 삭제시 자식도 삭제
ON UPDATE CASCADE, # 부모 수정시 자식도 수정
...)
Integrity Constraint Violation During Transactions
트랜잭션 중간에 무결성 제약조건이 위반된다면? SQL 표준에서는 Defer constraint checking(연기된 제약조건 검사)를 사용하여 트랜잭션이 끝날때 제약조건을 체크할 수 있습니다. SET Constraint 속성 DEFERRED;
Assertions
데이터베이스가 항상 만족해야하는 제약 조건을 설정할 수 있습니다.
# assertion 정의
# condition의 결과가 false가 되는 경우 reject
CREATE ASSERTION assertion_name CHECK (condition);
# "orders" 테이블에서 "quantity" 열 값이 0보다 큰지 검증하는 Assertion입니다.
CREATE ASSERTION quantity_check CHECK
(SELECT COUNT(*) FROM orders WHERE quantity > 0) > 0;
Built-in Data Types in SQL
date : 년, 월, 일 표현 YYYY-MM-DD 예시 ) '2005-7-27'
time : 시간, 분, 초 HH:MI:SS 예시 ) '09:00:30.75'
timestamp : date + time YYYY-MM-DD HH:MI:SS 예시 ) '2005-07-27 09:00:30.75'
interval : 기간을 표현합니다. 예시 ) '1' day
date/time/timestamp에 Interval 값을 더할 수 있습니다. 내일 = date() + interval'1'day
Large-Object Types
크기가 큰 객체들(사진, 비디오 등등)을 저장할 때 사용하는 타입입니다.
blob : binary large object - 사이즈가 큰 이진 데이터로 DB 시스템은 그저 큰 데이터를 저장하고, 해석은 담당 애플리케이션에서 수행합니다.
clob : character large object - 사이즈가 큰 문자열 데이터 타입입니다.
쿼리 결과로 lage-object를 반환할 때, large object를 그대로 반환하지 않고 그것의 포인터를 반환합니다.
User-Defined Types
사용자 정의 타입을 생성할 수 있습니다.
# Dollars 타입 생성
CREATE TYPE Dollars AS NUMERIC (12,2) FINAL
Domains
Domain을 직접 정의하여 쓸 수 있습니다.
Domain과 User-Defined Types는 속성이 가질 수 있는 값을 정의한다는 점에서 유사하지만 , User-Defined Types과 달리 Domain은 제약조건 정의, 기본값 지정 등이 가능합니다.
# Domain 정의 NOT NULL 제약조건을 지정할 수 있습니다.
CREATE DOMAIN person_name CHAR(20) NOT NULL
# 새로운 제약조건을 생성하여 Domain을 정의하기
CREATE DOMAIN degree_level VARCHAR(10)
CONSTRAINT degree_lever_test
CHECK( VALUE IN('Bachelors', 'Masters', 'Doctorate'));
Index Creation
인덱스란 데이터베이스 테이블의 데이터 검색 작업 속도를 향상시키는 자료 구조입니다.
큰 테이블, 자주 사용되는 검색 조건이 있는 속성(WHERE절에서 자주 사용되는 조건) , 자주 사용되는 JOIN 조건, 자주 갱신되지 않는 열에 인덱스를 생성하는 것이 좋습니다.
# 인덱스 정의
create index <name> on <relation-name> (attribute);
# Index Creation Example
create index studentID_index on student(ID)
# 다음 쿼리에서 검색 성능이 향상될 수 있습니다. ( 인덱스를 지정한 ID 속성으로 검색 )
select *
from student
where ID = '12345'
Authorization
Read / Insert / Update / Delete / allprivileges 권한이 존재합니다. 각각 투플에 관한 읽기 / 삽입 / 수정/ 삭제 / 모든 권한 을 나타냅니다.
릴레이션, 뷰와 같은 데이터베이스의 지정된 부분에 대해 사용자에게 모든 권한, 권한 없음 또는 여러 권한의 조합을 부여할 수 있습니다.
Authorization ( Cont. )
데이터베이스 스키마를 수정하는 권한입니다. Index -인덱스의 생성과 삭제 Resources - 새로운 릴레이션 생성 Alternation - 릴레이션에 속성 추가 혹은 속성 삭제 Drop - 릴레이션 삭제
Authorization Specification in SQL
GRANT절을 사용하여 권한을 부여할 수 있습니다.
# GRANT 권한 부여
grant <privilege list> on <relation or view > to <user list>
# GRANT example : SELECT 권한 부여
GRANT SELECT ON department To Amit, Satoshi;
user list에는 user-id , public ( 모든 사용자에게 권한 부여), role(해당 역할에 대해 권한 부여)가 있습니다.
View에 권한을 받았다고 해서 기반 테이블에는 접근할 수 없습니다.
Revoking Authorization in SQL
REVOKE를 사용하여 부여한 권한을 취소할 수 있습니다.
# REVOKE
revoke <privilege list> on <relation or view> from <user list>
<privilege-list>에 all을 쓰면 대상이 가질 수 있는 모든 권한을 취소하는 것입니다.
<revokee-list>에 public을 사용하면 public으로 권한을 부여 받은 사람은 취소됩니다.
만약 어떤 사람이 public으로 권한을 부여받고, 다른 사람으로부터 명시적으로 같은 권한을 부여받았다면 public이 revoke 되더라도 다른 권한이 살아있습니다.
권한이 취소되면 종속된 모든 권한들도 취소됩니다. 즉, A가 B에게 B가 C에게 권한을 부여한 경우 A의 권한이 취소되면 B, C의 권한도 취소됩니다.
Roles
유저에게 role을 부여하여 역할별로 권한을 부여할 수 있습니다.
역할을 생성하고, 해당 역할에 읽기 권한을 부여하면, 해당 역할을 가진 사용자는 전부 읽기 권한을 가질 수 있습니다.
# ROLE 생성
CREATE A ROLE <name>
# 생성한 역할을 사용자에게 부여
GRANT <role> to <users>
Roles Example
# 'instructor' Role 생성
create role instructor;
# Amit에게 'instructor' 역할 부여
grant instructor to Amit;
# Privileges can be granted to roles:
grant select on takes to instructor;
# role을 다른 role에게 부여할 수 있습니다.
# 이 경우 instructor은 teaching_assistant의 모든 권한을 상속받습니다.
create role teaching_assistant
grant teaching_assistant to instructor;
Other Authorization Features
references는 외래키를 생성할 수 있는 권한입니다.
외래키를 생성하면, 참조되는 릴레이션에 대한 삭제, 갱신이 제한될 수 있기 때문에 권한을 통해 관리하는 것이 적합합니다.
# reference example
grant reference (dept_name) on department to Mariano;
Outline 1. Overview of The SQL Query Language 2. SQL Data Definition 3. Basic Query Structure of SQL Queries 4. Additional Basic Operations 5. Set Operations 6. Null Values 7. Aggregate Functions 8. Nested Subqueries 9. Modification of the Database
SQL Parts
DML(Data Manipulation Language) : Database의 데이터 조회, 삽입, 수정, 삭제를 수행하는 언어 (SELECT /INSERT / UPDATE / DELETE )
DDL(Data Definition Language) :데이터베이스의 구조와 테이블, 뷰, 인덱스, 프로시저와 같은 개체를 정의합니다.
Integrity : DDL(Data Definition Language)에서 무결성 제약조건을 지정할 수 있습니다.
Transaction control : SQL에서 트랜잭션의 시작 (BEGIN TRANSACTION)과 끝(COMMIT)을 지정하여 트랜잭션을 조작할 수 있습니다. 이를 이용하여 회복 기법을 적용합니다.
Embedded SQL and Dynamic SQL : 범용 프로그래밍 언어에서 내장된 SQL을 정의하는 부분입니다.
Authorization ( 인가 ): 권한에 따라 릴레이션과 뷰에 접근을 통제하는 기능입니다.
Data Definition Language ( 데이터 정의어 )
각 릴레이션의 스키마 정의
각 속성에 대한 값의 타입 정의
무결성 제약조건 정의
각 릴레이션에 대한 인덱스 집합
각 릴레이션에 대한 보안(Security)과 인가(Authorization) 정보
각 릴레이션의 물리적 저장 구조 정의
Domain Types in SQL
char(n) : 길이가 n인 고정 길이의 문자열 타입
varchar(n) : 최대 길이가 n인 가변 길이문자열 타입
int : Integer 타입
smallint : Small Integer 타입
numeric(p,d) : 고정 소수점 숫자의 데이터 타입. p : 전체 자릿수, d : 소수점 오른쪽에 허용되는 자릿수 ex) numeric(3,1)인 경우 : 44.5 (o), 444.5(x), 0.32(x)
real, double precision : 실수형, 더블형 표현
float(n) : 실수형 표현, n이 전체 자릿수 및 스토리지 크기를 지정합니다. n값이 1~24인 경우 ) 자릿수 : 7자리 , 스토리지 크기 : 4바이트 n값이 25~53인 경우 ) 자릿수 : 15자리 , 스토리지 크기 : 8바이트
# instructor 테이블을 생성하는 SQL
CREATE TABLE instructor(
ID char(5),
name varchar(20) not null,
dept_name varchar(20),
salary numeric(8,2),
# 무결성 제약조건 지정
primary key (ID),
foreign Key (dept_name) references department);
instructor 테이블의 name 속성에 NOT NULL 제약조건 설정
ID 속성을 Primary Key로 설정
dept_name을 외래키로 설정 ( department를 참조 )
Updates to tables
투플 삽입 ( INSERT )
INSERY INTO instructor VALUES ('10211', 'Smith', 'Biology', 66000);
투플 삭제 ( DELETE )
# student 테이블의 투플 전체 삭제 SQL
DELETE FROM student;
# WHERE절을 추가하여 삭제할 투플의 조건을 지정할 수 있습니다.
# id 속성의 값이 3인 학생 삭제 SQL
DELETE FROM student WHERE id = 3;
테이블 삭제 ( DROP TABLE )
DROP TABLE instructor;
테이블 구조 변경 ( ALTER TABLE )
# instructor에 habit 속성을 추가하는 SQL, 기존에 있던 tuple에는 null 값이 채워지게 됩니다.
ALTER TABLE instructor ADD habit VARCHAR(20);
# 테이블 속성 삭제 - instructor에서 age 속성을 삭제하는 SQL문
# 속성을 삭제하는 SQL문은 지원하지 않는 데이터베이스가 많습니다.
ALTER TABLE instructor DROP age;
Basic Query Structure
SQL에서 "query"는 데이터베이스에서 정보를 가져오거나 수정하는 작업을 의미합니다. 쉽게 말해, 데이터베이스에 대해 질문하고 그에 대한 답을 받는 과정이라고 할 수 있습니다.
일반적으로 SQL에서 "query"는 SELECT 문을 사용하여 데이터를 가져오는 것을 의미합니다.
SQL query의 결과 값은 릴레이션입니다. ( 중첩하여 쿼리 가능 )
SELECT A1, A2, ..., An # 조회할 속성의 이름을 뜻합니다.
FROM r1, r2, ... ,rm # 릴레이션을 기술하며, 해당 릴레이션의 데이터를 가져옵니다.
WHERE P # P는 Predicate를 뜻합니다. 데이터 검색 조건이라고 생각할 수 있습니다.
# DISTINCT 키워드를 사용한 쿼리문
SELECT DISTINCT dept_name
FROM instructor
asterisk( * )을 사용하면 SELECT 절에 해당 릴레이션의 모든 속성을 명시하는 것과 동일합니다. 즉 릴레이션의 모든 데이터를 조회합니다.
FROM절 없이 SELECT 절만 사용하여 리터럴을 생성할 수 있습니다.
SELECT 절에는 +, -, *, / 등 산술 연산자가 들어갈 수 있습니다.
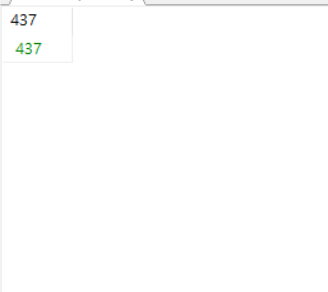
# 리터럴 생성구문
SELECT '437';
# as를 사용하여 별칭 지정 가능
SELECT '437' AS FOO;
# FROM절을 사용하여 리터럴 생성, instructor 테이블의 투플 수만큼 행이 생성됩니다.
SELECT 'A'
FROM instructor;
# SELECT 절에 산술 연산자를 사용하여 결과 값에는 각 salary를 12로 나눈 값이 들어갑니다
SELECT id, name, salary/12
FROM instructor;
실행 결과
The Where Clause
WHERE 절에는 결과가 만족해야하는 조건을 명시합니다.
관계 대수에서 σ에 해당합니다.
AND, OR, NOT를 사용하여 여러 조건절들을 연결할 수 있습니다.
비교 연산자를 사용할 수 있습니다. <, <=, >, >=, =, <>
# Comp. Sci.에 속하며 salary가 70000을 초과하는 모든 instructors의 name 조회하기
SELECT name
FROM instructor
WHERE dept_name = 'Comp. Sci.' AND salary > 70000;
The From Clause
쿼리와 관련된 관계를 나열합니다.
관계 대수의 X에 해당합니다. ( Cartesian product )
두 릴레이션에서 발생할 수 있는 모든 쌍을 생성합니다.
공통 속성(예: ID)의 경우 결과 테이블의 속성 이름이 릴레이션이름(예: instructor.ID)을 사용하여 변경됩니다
CartesianProduct는 단독적으로 사용하기 보다는, WHERE절과 함께 사용하는 것이 성능으로 좋습니다.
# 두 릴레이션에서 ID가 같은 데이터를 조회
SELECT name, course_id
FROM instructor, teaches
where instructor.ID = teaches.ID;
The Rename Clause
쿼리문에서 as구문을 사용하여 릴레이션과 속성의 이름을 바꿀 수 있습니다. ( 원본 릴레이션의 이름을 바꾸기 위해서는 RENAME 명령어를 사용해야합니다.)
Oracle에서는 from 절에서 as를 생략해야합니다. FROM instruct T
# salary가 'Comp.Sci.'부서 사람들보다 높은 사람들 조회하기
# as를 사용하여 별칭을 지정합니다. ( instructor -> T )
SELECT distinct T.name
FROM instructor as T, instructor as S
WHERE T.salary > S.salary and S.dept_name = 'Comp.Sci.';
String Operations
문자열 패턴 비교 연산자: LIKE
Percent ( % ) : any substring
underscore ( _ ) : any character
"%"를 포함한 문자열을 조회하려면 Escape를 사용해야합니다. LIKE '100\%' escape '\'; ( '\'가 아닌 다른 문자를 사용해도 가능합니다. )
"||" : Concatenation ( 문자열 결합 연산자 )
LOWER(str) : upper case를 lower case로 바꿈
Trim() : 문자열 양쪽에서 공백을 제거하는 함수
# "dar"을 포함하는 문자열 찾기
SELECT name
FROM instructor
WHERE name LIKE '%dar%';
Pattern matching examples:
'Intro%' : "intro"로 시작하는 모든 문자열
'%comp%' : "comp"를 부분 문자열로 가진 모든 문자열
'___' : 길이가 3인 모든 문자열
'___%' : 길이가 3이상인 모든 문자열
Ordering the Display of Tuples
ORDER BY 키워드를 사용하여 투플을 정렬할 수 있습니다.
ASC, DESC 속성을 사용하면 오름차순, 내림차순을 지정할 수 있습니다. ( Default : ASC)
속성을 여러개 나열하여 여러 기준으로 정렬이 가능합니다.
# dept_name으로 오름차순 정렬 후, dept_name이 같으면 name으로 내림차순 정렬
SELECT name
FROM instructor
ORDER BY dept_name ASC, name DESC;
Where Clause Predicates
BEWTEEN : 범위를 지정하는 키워드입니다.
# salary >= 90000 and salary <= 100000
SELECT name
FROM instructor
WHERE salary BETWEEN 90000 AND 100000;
투플 집합 비교 연산
# 투플 집합 비교 연산 오라클은 지원하지 않습니다.
SELECT name, course_id
FROM instructor, teaches
WHERE (instructor.ID, dept_name) =(teaches.ID, 'Biology');
Set Operations
UNION / INTERSECT /EXCEPT
집합 연산자는 기본적으로 중복을 제거합니다.
중복되는 속성을 유지하려면 all 키워드를 사용합니다. UNION ALL / INTERSECT ALL / EXCEPT ALL
# 합집합 연산
(SELECT course_id FROM section WHERE sem ='Fall' AND year=2017)
UNION
(SELECT course_id FROM section WHERE sem ='Spring' AND year=2018)
Null values
null은 '알수 없는 값' 혹은 '값이 없음'을 나타냅니다.
null을 포함한 산술 연산의 결과 값은 항상 null입니다. 예시) 5 + null returns null
Predicate에서 null 값 확인하는 방법 : IS NULL / IS NOT NULL
SELECT name
FROM instructor
WHERE salary IS NULL;
Null values (Cont.)
IS NULL , IS NOT NULL을 제외한 비교 연산자에 null 값이 있는 경우 결과는 전부 null로 처리 예시) 5 < null or null <> null or null = null
where문 내부 술어에서는 논리 연산 AND, OR, NOT을 사용할 수 있습니다. null에 대한 해당 연산의 결과는 다음과 같습니다.
and
(ture AND unknown) = unknown,
(false AND unknown) = false,
(unknown AND unknown) = unknown
or
(unknown OR true) = true,
(unknown OR false) = unknown,
(unknown OR unknown) = unknown
Aggregate Functions ( 집계 함수 )
avg : 평균값 null 값이 있는 투플은 전체 계산에서 빼고 진행
min : 최솟값
max : 최댓값
sum : 값의 합을 반환, null 값이 있는 투플은 빼고 더합니다.
count : 투플의 개수를 반환합니다. count(속성명) : 해당 속성값이 null인 경우는 세지 않습니다. count(*) : null을 포함한 전체 투플의 수를 셉니다. count( distinct 속성 ) : 중복값을 제외하고 수를 셉니다.
Aggregate Functions - Group By
Group By 키워드를 사용하면 지정한 속성의 공통값으로 그룹을 지어 집계할 수 있습니다.
Group By 절을 사용하면 SELECT에는 Group By 속성과 집계함수만 들어갈 수 있습니다.
# 부서 별 평균 봉급
SELECT dept_name, AVG (salary) as avg_salary
FROM instructor
Group By dept_name;
# SELECT 절에 GROUP BY 에 나열되지 않은 속성(ID)이 오는 경우 ERROR
/* erroneous query */
SELECT dept_name, ID, AVG (salary)
FROM instructor
Group By dept_name;
Aggregate Functions - Having Clause
Group By 절에 Having 절을 사용하여 조건을 추가할 수 있습니다.
# 부서별 평균 봉급이 42000원보다 큰 부서명과 평균 봉급을 조회하는 쿼리
select dept_name, avg (salary) as avg_salary
from instructor
group by dept_name
having avg (salary) > 42000;
쿼리 수행 순서 FROM - WHERE - GROUP BY - HAVING - SELECT - ORDER BY
Nested Subqueries
서브 쿼리는 query안에 선언된 또다른 select-from-where절을 말합니다.
SELECT A1, A2, ..., An
FROM r1, r2, ..., rm
WHERE P
Subquery 사용 위치 FROM절 - 인라인 뷰 ( Inline views ) WHERE절 - 중첩서브쿼리 ( Nested subqueries ) SELECT절 - 스칼라서브쿼리 ( scala subquery ) , 단일 값만을 리턴해야합니다 ( 레코드 1개 )
Set Membership
IN : 주어진 집합에 속하는 경우를 참
NOT IN : 주어진 집합에 속하지 않는 경우에 참
# 2017년 가을과 2018년 봄 모두 제공된 코스를 불러오는 쿼리
SELECT DISTINCT course_id
FROM section
WHERE semester = 'Fall' and year= 2017 and
course_id in (select course_id
from section
where semester = 'Spring' and year= 2018
);
# 집합간 비교
SELECT COUNT (DISTINCT ID)
FROM takes
WHERE (course_id, sec_id, semester, year) in
(SELECT course_id, sec_id, semester, year
FROM teaches
WHERE teaches.ID= 10101);
Set Comparison
Set Comparison – “some” Clause
# Biology 학과의 일부 강사(최소 한 명)보다 급여가 많은 강사의 이름을 찾습니다.
select name
from instructor
where salary > some (
select salary
from instructor
where dept name = 'Biology');
5 < some(0,5,6) true
5 < some(0,5) false
5 = some(0,5) true # 5 In (0,5) 와 같습니다
5 <> some(0,5) true # 0 != 5, 즉 하나의 투플이라도 다르다면 true입니다. NOT IN 과 다릅니다.
Set Comparison – “all” Clause
# Biology의 모든 instructor의 salary보다 salary가 더 큰 instructor 조회
select name
from instructor
where salary > all
(select salary
from instructor
where dept name = 'Biology');
5 < all (0,5,6) false
5 < all (6,10) true
5 = all (4,5) false # 하나라도 다른 게 있으면 false, IN과 다릅니다.
5 <> all (4,6) true # 4,6모두 5와 다르므로 true, NOT IN과 동일합니다.
Use of “exists” Clause
subquery 결과가 존재하면 true
# Fall 2017, Spring 2018 학기에 둘다 열린 강의 조회
SELECT course_id
FROM section AS S
WHERE semester = 'Fall' AND year = 2017 AND
EXISTS ( SELECT *
FROM section AS T
WHERE semester = 'Spring' AND year = 2018
AND S.course_id = T.course_id);
Use of “not exists” Clause
# Biology 학과의 모든 과목을 수강한 학생을 조회
SELECT DISTINCT S.ID, S.name
FROM student AS S
WHERE NOT EXISTS (( SELECT course_id # 첫번째 subquery는 'Biology'의 모든 과목을 불러옵니다.
FROM course
WHERE dept_name = 'Biology')
EXCEPT
( SELECT T.course_id # 두번째 subquery는 학생이 들은 모든 코스를 가져옵니다.
FROM takes AS T
WHERE S.ID = T.ID));
EXISTS vs IN
EXISTS는 메인쿼리에서 하나의 레코드를 가져와 해당 레코드로 서브 쿼리를 실행했을 때 결과가 존재하는지 확인합니다.
IN은 서브쿼리를 먼저 실행한 후, 메인 쿼리의 레코드를 하나씩 가져와서 서브쿼리 결과 요소들과 비교하여 존재하는지 확인합니다.
Test for Absence of Duplicate Tuples
UNIQUE를 사용하면 subquery의 결과에 중복이 있는지 확인할 수 있습니다.
주어진 subquery 결과에 중복이 존재하지 않으면 참, 중복이 존재하면 거짓입니다.
# 2017년에 한 번만 제공된 course 찾는 쿼리
SELECT T.course_id
FROM course AS T
WHERE UNIQUE ( SELECT R.course_id
FROM section AS R
WHERE T.course_id = R.course_id
AND R.year = 2017 );
Subqueries in the Form Clause
# 평균 급여가 42000보다 큰 학과의 평균 강사 급여 조회
SELECT dept_name, avg_salary
FROM ( SELECT dept_name, AVG(salary) AS avg_salary
FROM instructor
GROUP BY dept_name)
WHERE avg_salary > 42000;
With Clause
with 절은 with절이 사용되는 쿼리에서 사용될 임시 릴레이션을 정의할 때 사용합니다.
# Maximum budget을 가진 모든 부서 조회
WITH max_budget(value) AS # subquery를 임시 릴레이션 max_budget으로 사용
(SELECT MAX(budget)
FROM department)
SELECT department.name
FROM department, max_budget
WHERE department.budget = max_budget.value;
Complex Queries using With Clause
# 부서별 총 급여가 모든 부서의 총 급여 평균보다 큰 부서 조회하기
# 임시 릴레이션을 2개 생성 - dept_total, dept_total_avg
WITH dept_total(dept_name, value) AS # subquery1 : 부서별 총합 급여
( SELECT dept_name, SUM(salary)
FROM instructor
GROUP BY dept_name),
dept_total_avg(value) AS # subquery2 : 부서별 총합 급여의 평균값
( SELECT AVG(value)
FROM dept_total)
SELECT dept_name
FROM dept_total, dept_total_avg
WHERE dept_total.value > dept_total_avg.value;
Scalar Subquery
SELECT 절에 사용되는 서브쿼리로, 결과값이 1개의 투플을 반환해야 합니다.
스칼라 서브쿼리가 2개 이상의 투플을 반환하는 경우 런타임에러가 발생합니다.
# 학과와 그 학과의 강사 수 조회
SELECT dept_name,
( SELECT COUNT(*)
FROM instructor
WHERE department.dept_name = instructor.dept_name)
AS num_instructors
FROM department;
Modification of the Database
Deletion
# 모든 instructor 삭제
DELETE FROM instructor
# 'Finance'학과 모든 instructor 삭제
DELETE FROM instructor
WHERE dept_name = 'Finance';
# 'Watson'빌딩에 위치한 학과의 모든 instructor 삭제
DELETE FROM instructor
WHERE dept_name IN (SELECT dept_name
FROM department
WHERE building = 'Watson');
# 평균 salary보다 적은 salary인 모든 instructor 삭제
DELETE FROM instructor
WHERE salary < (SELECT AVG(salary)
FROM instructor);
Insertion
# Course에 새로운 투플 삽입
INSERT INTO course
VALUES('CS-437','Database Systems', 'Comp. Sci.', 4);
# 또는
INSERT INTO course (course_id, title, dept_name, credits)
VALUES('CS-437','Database Systems', 'Comp. Sci.', 4);
# null 값을 가진 투플 삽입하기
INSERT INTO student
VALUES('3003', 'Green', 'Finance', null);
# 144학점 넘게 들은 student를 임금이 $18000인 Instructor로 만들기
INSERT INTO instructor
SELECT ID, name, dept_name, 18000
FROM student
WHERE dept_name = 'Music' AND total_cred > 144;
# SELECT FROM WHERE 문은 반드시 결과 값이 삽입되기 이전에 수행되는 것을 보장받습니다.
# 그렇지 않으면 다음과 같이 릴레이션의 값을 복사하는 쿼리에서 문제가 발생할 수 있습니다.
INSERT INTO table1 SELECT * FROM table1;
Updates
# 모든 instructor의 salary를 5%씩 인상시키기
UPDATE instructor
SET salary = salary * 1.05;
# salary < 70000인 모든 instructor의 salary를 5%씩 인상시키기
UPDATE instructor
SET salary = salary * 1.05;
WHERE salary < 70000;
# salary가 평균 salary보다 작은 모든 instructor의 salary를 5%씩 인상시키기
UPDATE instructor
SET salary = salary * 1.05
WHERE salary < (SELECT AVG(salary)
FROM instructor);
# salary > 100000이면 3%, 그렇지 않으면 5% 인상시키기
# UPDATE문을 두번 사용합니다. 만약 순서가 뒤바뀌면 돈이 두번 인상될 가능성이 존재합니다.
# 이런 경우 CASE 문을 사용하는 것을 권장합니다.
UPDATE instructor
SET salary = salary * 1.03
WHERE salary > 100000;
UPDATE instructor
SET salary = salary * 1.05
WHERE salary <= 100000;
Case Statement for Conditional Updates
UPDATE instructor
SET salary = CASE
WHEN salary <= 100000 THEN salary * 1.05
ELSE salary * 1.03
END
Updates with Scalar Subqueries
# 모든 학생들의 tot_creds를 계산하고, update하는 예시
UPDATE student S
SET tot_cred = (SELECT SUM(credits)
FROM takes, course
WHERE takes.course_id = course.course_id AND
S.ID = takes.ID AND
takes.grade <> 'F' AND
takes.grade IS NOT NULL);
# CASE 문 사용하는 방법
UPDATE student S
SET tot_cred = CASE
WHEN SUM(credits) IS NOT NULL THEN SUM(credits)
ELSE 0
END
Outline 1. Structure of Relational Databases 2. Database Scheme 3. Keys 4. Schema Diagrams 5. Relational Query Languages 6. The Relational Algebra
1. Structure of Relational Databases
Relation Schema and Instance
A1, A2, ..., An이라는 속성이 있을 때 릴레이션의 표현 방법
R = (A1,A2, ..., An)
ex) Instructor = ( ID, name, dept_name, salary)
릴레이션 R의 인스턴스인 r의 표기 방법 : r(R)
Attributes ( 속성 )
속성은 RDB에서 정보를 표현하는 가장 작은 단위입니다.
각 속성이 가질 수 있는 값의 집합 : Domain
일반적으로 도메인에 의해 정해지는 속성 값은 더 작게 쪼개지지 않는 원자적인(atomic) 성질을 가져야 합니다.
모든 도메인에는 Null 값을 포함하고 있으며, Null은 정해지지 않은 값을 의미합니다.
Relations are Unordered
- 릴레이션의 투플은 별도의 순서를 가지고 있지 않습니다. ( 임의의 순서로 저장될 수 있습니다.)
2. Database Schema
Database Schema는 데이터베이스의 논리적인 구조를 의미합니다. Database Instance는 특정 시점에 데이터베이스에 저장되어있는 데이터를 의미합니다 ( snapshot of the data) 즉, 스키마는 데이터베이스의 논리적 구조를 바꾸지 않으면 변화가 없지만, 인스턴스는 매 순간마다 달라질 수 있습니다.
Super Key 예시 : 위 테이블에서 {ID}와 {ID, name} 속성은 모두 수퍼키입니다. ( 각 테이블을 식별할 수 있음 )
Candidate Key : Super Key 중에서 투플을 식별할 수 있는 최소한의 속성만을 가진 집합 ( 유일성 + 최소성 )
Candidat Key 예시 : {ID} 속성만으로 투플을 식별할 수 있으므로, {ID}는 후보키입니다.
Primary Key : Candidate Key 중에서 하나를 선택하여 Primary key로 지정합니다. 해당 속성은 null 값을 가질 수 없습니다.( 유일성 + 최소성 + NOTNULL)
위 예시에서는 {ID} 속성을 Primary Key로 지정할 수 있습니다.
Foregin Key : 하나(또는 여러개)의 다른 릴레이션의 기본키(PK) 필드를 참조하는 데이터의 참조 무결성(Referential integrity)을 확인하기 위해 사용되는 키(Key)
Foreign Key Constraint ( 외래키 제약조건)
외래키(Foreign Key) 제약조건은 관계형 데이터베이스에서 하나의 테이블의 컬럼(속성)이 다른 테이블의 기본키(Primary Key)를 참조하는 제약조건입니다. 쉽게 말하면, 외래키가 가질 수 있는 값은 속성의 기존( 참조 되는 릴레이션에서의 ) 도메인값 + null 값입니다.
Referencing relation : 참조하는 릴레이션
Referenced relation : 참조되는 릴레이션
4. Schema Diagram
University 데이터베이스에서의 스키마 다이어그램은 다음과 같이 Entity ( 릴레이션 ) + Relationship( 화살표 )로 표현합니다.
Entity : 엔티티(entity)는 데이터베이스에 표현하려고 하는 유형, 무형의 객체로서 서로 구별되는 것을 뜻합니다.
Relationship : 관계(Relationship)는 두 개 이상의 데이터베이스 테이블 사이에 논리적 연관성을 의미합니다.
5. Relational Query Languages
Relational Query Language는 사용자가 데이터베이스와 통신하는 데 사용되는 언어입니다.
다른 프로그래밍 언어보다 더 높은 수준에 있습니다. ( 고급 언어 )
명령형 언어 (ImperativeLanguage) 와 선언형언어 ( DeclarativeLanguage)로 나뉘며 이는 절차적언어(ProceduralLanguage)와 비절차적언어( Non-proceduralLanguage)로 구분하기도 합니다.
명령형언어 : 명령형 언어는 컴퓨터에 직접적으로 수행할 명령어를 지시합니다.
선언형언어 : 선언형 언어는 원하는 결과를 기술하는 방식으로 질의합니다. ( 시스템이 필요한 결과를 얻기 위해 필요한 명령어를 자동으로 생성해줍니다. ) ex) SQL,
6 . Relational Algebra
관계 대수( Relational Algebra )는 절차적언어( Procedural Language)입니다. 하나 또는 두개의 릴레이션을 대상으로 하는 연산을 수행하며 그 결과로 하나의 새로운 릴레이션을 생성합니다. ( Input과 Output이 모두 릴레이션이므로 중첩하여 사용 가능 )
Select : σ , 단항 연산자
Project : π , 단항 연산자
Union : U , 이항 연산자
setdifference : - , 이항 연산자
Cartesianproduct : X , 이항 연산자
rename : ρ , 단항 연산자
Select Operation
select 연산자는 주어진 조건을 만족하는 투플들을 반환하는 연산자입니다.
표기방법 : σp ( r )
p는 selection predicate를 의미합니다. 내부에 비교 연산자를 사용할 수 있고, 비교 연산자를 통해 여러가지 술어들을 나열할 수 있습니다.
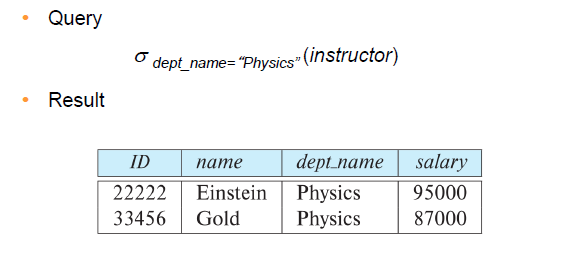
EX ) "Physics" 부서에서 근무하는 instructor을 select 하는 연산은 다음과 같습니다.
Project Operation
Project 연산자는 나열되지 않은 특정 속성을 제외한 릴레이션을 반환하는 연산자입니다.
연산의 결과로 중복되는 행이 제거됩니다.
EX ) dept_name 속성을 제외한 릴레이션을 project 하는 연산은 다음과 같습니다.
Composition of Relational Operations
관계 대수 연산의 결과는 릴레이션이므로 관계 대수 연산의 결과가 관계 대수식에 포함될 수 있습니다. ( 중첩 가능 )
다음의 연산은 "Physics" 부서에서 일하는 instructor의 name을 반환합니다.
Cartesian Product Operation
Cartesian Product 연산은 이항 연산자로 두 테이블을 결합하는 연산입니다.
두 테이블의 데이터에서 생성 가능한 모든 짝을 지어 반환합니다.
Instructor 테이블과 Teaches 테이블의 Cartesian Product 연산은 다음과 같이 표현합니다.
Join Operation
Join 연산자는 두 개 이상의 릴레이션에서 공통 속성을 기반으로 데이터를 결합하는 연산자입니다.
표현 방법 : R ⨝<sub>C</sub> S
Join 연산 과정
Join 조건에 따라 R과 S 릴레이션에서 공통 속성을 추출합니다.
추출한 공통 속성을 기반으로 릴레이션들을 결합합니다.
Join된 결과 릴레이션을 반환합니다.
조인 연산을 이용하면 Select + Cartesian-Product 연산을 한꺼번에 수행할 수 있습니다.
아래 두 식은 같은 결과를 반환합니다.
Union Operation
이항 연산자로, 두 릴레이션을 결합하는 연산자입니다. ( 합집합 연산 )
r U s
Union Operation을 수행하기 위한 조건
1. r,s의 arity가 같아야 합니다. ( same number of attributes )
2. 서로 대응되는 속성의 도메인이 같아야 합니다. ( compatible )
EX ) to find all courses taught in the Fall 2017 semester, or in the Spring 2018 semester, or in both
실행결과
Set Intersection Operation
교집합 연산으로, 두 테이블이 모두 가지고 있는 투플을 반환합니다.
합집합 연산과 동일한 조건이 필요합니다. ( same arity & compatible )
Set Intersection Operation
차집합 연산을 수행합니다. 하나의 테이블만 가지고 있고, 다른 테이블에는 없는 투플을 반환합니다.
r - s
must be Same arity & compatible
The Assignment Operation
Assignment 연산을 통해 관계 변수에 관계 대수 연산의 일부분을 저장할 수 있습니다.
←
프로그래밍 언어에서 변수에 값을 저장하는 것과 유사합니다.
The Rename Operation
Rename 연산을 통해 관계 대수 연산의 결과로 생성된 릴레이션의 이름을 지정할 수 있습니다.
Px ( E )
Expression E의 이름을 x 지정합니다.
Px(A1, A2, ... , An) ( E )와 같이 이름 x와 속성의 이름들(A1,A2, ... , An)을 지정할 수 있습니다.
Equivalent Queries
Example 1: Find information about courses taught by instructors in the Physics department with salary greater than 90,000
두 쿼리는 동일하지 않지만 어떤 데이터베이스에서든 같은 결과를 반환합니다.
Example 2: Find information about courses taught by instructors in the Physics department